2024-03-31 14:51:57 +02:00
{
"cells": [
{
"cell_type": "code",
2024-04-09 10:14:05 +02:00
"execution_count": 71,
2024-03-31 14:51:57 +02:00
"metadata": {},
"outputs": [],
"source": [
"import gc\n",
"import os\n",
"import cv2\n",
"import math\n",
"import base64\n",
"import random\n",
"import numpy as np\n",
"from PIL import Image \n",
"from tqdm import tqdm\n",
"from datetime import datetime\n",
"import matplotlib.pyplot as plt\n",
"\n",
"import torch\n",
"import torch.nn as nn\n",
"from torch.cuda import amp\n",
"import torch.nn.functional as F\n",
"from torch.optim import Adam, AdamW\n",
"from torch.utils.data import Dataset, DataLoader\n",
"\n",
"import torchvision\n",
"import torchvision.transforms as TF\n",
"import torchvision.datasets as datasets\n",
"from torchvision.utils import make_grid\n",
"\n",
"from torchmetrics import MeanMetric\n",
"\n",
"from IPython.display import display, HTML, clear_output\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Helper functions"
]
},
{
"cell_type": "code",
2024-04-09 10:14:05 +02:00
"execution_count": 72,
2024-03-31 14:51:57 +02:00
"metadata": {},
"outputs": [],
"source": [
"def to_device(data, device):\n",
" \"\"\"将张量移动到选择的设备\"\"\"\n",
" \"\"\"Move tensor(s) to chosen device\"\"\"\n",
" if isinstance(data, (list, tuple)):\n",
" return [to_device(x, device) for x in data]\n",
2024-04-01 12:38:50 +02:00
" return data.to(device, non_blocking=True)"
2024-03-31 14:51:57 +02:00
]
},
{
"cell_type": "code",
2024-04-09 10:14:05 +02:00
"execution_count": 73,
2024-04-01 00:16:59 +02:00
"metadata": {},
"outputs": [],
"source": [
"class DeviceDataLoader:\n",
" \"\"\"包装一个数据加载器,来把数据移动到另一个设备上\"\"\"\n",
" \"\"\"Wrap a dataloader to move data to a device\"\"\"\n",
"\n",
" def __init__(self, dl, device):\n",
" self.dl = dl\n",
" self.device = device\n",
"\n",
" def __iter__(self):\n",
" \"\"\"在移动到设备后生成一个批次的数据\"\"\"\n",
" \"\"\"Yield a batch of data after moving it to device\"\"\"\n",
" for b in self.dl:\n",
" yield to_device(b, self.device)\n",
"\n",
" def __len__(self):\n",
" \"\"\"批次的数量\"\"\"\n",
" \"\"\"Number of batches\"\"\"\n",
" return len(self.dl)"
]
},
{
"cell_type": "code",
2024-04-09 10:14:05 +02:00
"execution_count": 74,
2024-04-01 00:16:59 +02:00
"metadata": {},
"outputs": [],
"source": [
"def get_default_device():\n",
" return torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")"
]
},
{
"cell_type": "code",
2024-04-09 10:14:05 +02:00
"execution_count": 75,
2024-04-01 00:16:59 +02:00
"metadata": {},
"outputs": [],
"source": [
"def save_images(images, path, **kwargs):\n",
" grid = make_grid(images, **kwargs)\n",
" ndarr = grid.permute(1,2,0).to(\"cpu\").numpy()\n",
" im = Image.fromarray(ndarr)\n",
" im.save(path)"
]
},
{
"cell_type": "code",
2024-04-09 10:14:05 +02:00
"execution_count": 76,
2024-04-01 00:16:59 +02:00
"metadata": {},
"outputs": [],
"source": [
"def get(element: torch.Tensor, t: torch.Tensor):\n",
" \"\"\"\n",
" Get value at index position \"t\" in \"element\" and \n",
" reshape it to have the same dimension as a batch of images\n",
"\n",
" 获得在\"element\"中位置\"t\"并且reshape,
" \"\"\"\n",
" ele = element.gather(-1, t)\n",
" return ele.reshape(-1, 1, 1, 1)"
]
},
{
"cell_type": "code",
2024-04-09 10:14:05 +02:00
"execution_count": 77,
2024-04-01 00:16:59 +02:00
"metadata": {},
"outputs": [],
"source": [
"element = torch.tensor([[1,2,3,4,5],\n",
" [2,3,4,5,6],\n",
" [3,4,5,6,7]])\n",
"t = torch.tensor([1,2,0]).unsqueeze(1)"
]
},
{
"cell_type": "code",
2024-04-09 10:14:05 +02:00
"execution_count": 78,
2024-04-01 00:16:59 +02:00
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"tensor([[1, 2, 3, 4, 5],\n",
" [2, 3, 4, 5, 6],\n",
" [3, 4, 5, 6, 7]])\n",
"tensor([[1],\n",
" [2],\n",
" [0]])\n"
]
}
],
"source": [
"print(element)\n",
"print(t)"
]
},
{
"cell_type": "code",
2024-04-09 10:14:05 +02:00
"execution_count": 79,
2024-03-31 14:51:57 +02:00
"metadata": {},
"outputs": [
{
2024-04-01 00:16:59 +02:00
"name": "stdout",
"output_type": "stream",
"text": [
"tensor([[[[2]]],\n",
"\n",
"\n",
" [[[4]]],\n",
"\n",
"\n",
" [[[3]]]])\n"
2024-03-31 14:51:57 +02:00
]
}
],
2024-04-01 00:16:59 +02:00
"source": [
"extracted_scores = get(element, t)\n",
"print(extracted_scores)"
]
},
{
"cell_type": "code",
2024-04-09 10:14:05 +02:00
"execution_count": 80,
2024-04-01 00:16:59 +02:00
"metadata": {},
"outputs": [],
"source": [
"def setup_log_directory(config):\n",
" \"\"\"\n",
" Log and Model checkpoint directory Setup\n",
" 记录并且建模目录准备\n",
" \"\"\"\n",
"\n",
" if os.path.isdir(config.root_log_dir):\n",
" # Get all folders numbers in the root_log_dir\n",
" # 在root_log_dir下获得所有文件夹数目\n",
" folder_numbers = [int(folder.replace(\"version_\", \"\")) for folder in os.listdir(config.root_log_dir)]\n",
"\n",
" # Find the latest version number present in the log_dir\n",
" # 找到在log_dir下的最新版本数字\n",
" last_version_number = max(folder_numbers)\n",
"\n",
" # New version name\n",
" version_name = f\"version{last_version_number + 1}\"\n",
"\n",
" else:\n",
" version_name = config.log_dir\n",
"\n",
" # Update the training config default directory\n",
" # 更新训练config默认目录\n",
" log_dir = os.path.join(config.root_log_dir, version_name)\n",
" checkpoint_dir = os.path.join(config.root_checkpoint_dir, version_name) \n",
"\n",
" # Create new directory for saving new experiment version\n",
" # 创建一个新目录来保存新的实验版本\n",
" os.makedirs(log_dir, exist_ok=True)\n",
" os.makedirs(checkpoint_dir, exist_ok=True)\n",
"\n",
" print(f\"Logging at: {log_dir}\")\n",
" print(f\"Model Checkpoint at: {checkpoint_dir}\")\n",
"\n",
" return log_dir, checkpoint_dir\n"
]
},
{
"cell_type": "code",
2024-04-09 10:14:05 +02:00
"execution_count": 81,
2024-04-01 12:38:50 +02:00
"metadata": {},
"outputs": [],
"source": [
"def frames2vid(images, save_path):\n",
"\n",
" WIDTH = images[0].shape[1]\n",
" HEIGHT = images[0].shape[0]\n",
"\n",
" # fourcc = cv2.VideoWriter_fourcc(*'XVID')\n",
" fourcc = cv2.VideoWriter_fourcc(*'mp4v')\n",
" video = cv2.VideoWriter(save_path, fourcc, 25, (WIDTH, HEIGHT))\n",
"\n",
" # Appending the images to the video one by one\n",
" # 一个接一个的将照片追加到视频\n",
" for image in images:\n",
" video.write(image)\n",
" \n",
" # Deallocating memories taken for window creation\n",
" # 释放创建window占用的内存\n",
" \n",
" video.release()\n",
" return\n",
"\n",
"def display_gif(gif_path):\n",
" b64 = base64.b64encode(open(gif_path,'rb').read()).decode('ascii')\n",
" display(HTML(f'<img src=\"data:image/gif;base64,{b64}\" />'))\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Configurations"
]
},
{
"cell_type": "code",
2024-04-09 10:14:05 +02:00
"execution_count": 82,
2024-04-01 00:16:59 +02:00
"metadata": {},
"outputs": [],
2024-03-31 14:51:57 +02:00
"source": [
"from dataclasses import dataclass\n",
"\n",
"@dataclass\n",
"class BaseConfig:\n",
" DEVICE = get_default_device()\n",
" DATASET = \"Flowers\" #MNIST \"cifar-10\" \"Flowers\"\n",
"\n",
" # 记录推断日志信息并保存存档点\n",
" root_log_dir = os.path.join(\"Logs_Checkpoints\", \"Inference\")\n",
" root_checkpoint_dir = os.path.join(\"Logs_Checkpoints\",\"checkpoints\")\n",
"\n",
" #目前的日志和存档点目录\n",
" log_dir = \"version_0\"\n",
" checkpoint_dir = \"version_0\"\n",
"\n",
"@dataclass\n",
"class TrainingConfig:\n",
" TIMESTEPS = 1000\n",
" IMG_SHAPE = (1,32,32) if BaseConfig.DATASET == \"MNIST\" else (3,32,32)\n",
" NUM_EPOCHS = 800\n",
" BATCH_SIZE = 32\n",
" LR = 2e-4\n",
" NUM_WORKERS = 2"
]
2024-04-01 12:38:50 +02:00
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Load Dataset & Build Dataloader"
]
},
{
"cell_type": "code",
2024-04-09 10:14:05 +02:00
"execution_count": 83,
2024-04-01 12:38:50 +02:00
"metadata": {},
"outputs": [],
"source": [
"def get_dataset(dataset_name='MNIST'):\n",
" \"\"\"\n",
" Returns the dataset class object that will be passed to the Dataloader\n",
" Three preprocessing transforms,\n",
" and one augmentation are applied to every image in the dataset\n",
" 返回数据集的类对象\n",
" 这个类对象将会被传递给DataLoader\n",
" 数据集中的每个图象将会应用三个预处理转换\n",
" 和一个增强\n",
" \"\"\"\n",
" transforms = TF.Compose(\n",
" [\n",
" TF.ToTensor(),\n",
" TF.Resize((32,32),\n",
" interpolation=TF.InterpolationMode.BICUBIC,\n",
" antialias=True),\n",
" TF.RandomHorizontalFlip(),\n",
" TF.Lambda(lambda t: (t * 2) - 1) # scale between [-1, 1]\n",
" ]\n",
" )\n",
"\n",
" if dataset_name.upper() == \"MNIST\":\n",
" dataset = datasets.MNIST(root=\"data\", train=True, download=True, transform=transforms)\n",
" elif dataset_name == \"Cifar-10\":\n",
" dataset = datasets.CIFAR10(root=\"data\", train=True,download=True, transform=transforms)\n",
" elif dataset_name == \"Cifar-100\":\n",
" dataset = datasets.CIFAR10(root=\"data\", train=True,download=True, transform=transforms)\n",
" elif dataset_name == \"Flowers\":\n",
" dataset = datasets.ImageFolder(root=\"data/flowers\", transform=transforms)\n",
" return dataset"
]
},
{
"cell_type": "code",
2024-04-09 10:14:05 +02:00
"execution_count": 84,
2024-04-01 12:38:50 +02:00
"metadata": {},
"outputs": [],
"source": [
"def get_dataloader(dataset_name='MNIST',\n",
" batch_size=32,\n",
" pin_memory=False,\n",
" shuffle=True,\n",
" num_workers=0,\n",
" device=\"cpu\"\n",
" ):\n",
" dataset = get_dataset(dataset_name=dataset_name)\n",
" dataLoader = DataLoader(dataset, batch_size=batch_size,\n",
" pin_memory=pin_memory,\n",
" num_workers=num_workers,\n",
" shuffle=shuffle\n",
" )\n",
" device_dataloader = DeviceDataLoader(dataLoader, device)\n",
" return device_dataloader"
]
},
{
"cell_type": "code",
2024-04-09 10:14:05 +02:00
"execution_count": 85,
2024-04-01 12:38:50 +02:00
"metadata": {},
"outputs": [],
"source": [
"def inverse_transform(tensors):\n",
" \"\"\"\n",
" Convert tensors from [-1., 1.] to [0., 255.]\n",
" \"\"\"\n",
" return ((tensors.clamp(-1, 1) + 1.0) / 2.0) * 255.0"
]
},
{
"cell_type": "code",
2024-04-09 10:14:05 +02:00
"execution_count": 86,
2024-04-01 12:38:50 +02:00
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Dataset ImageFolder\n",
" Number of datapoints: 4317\n",
" Root location: data/flowers\n",
" StandardTransform\n",
"Transform: Compose(\n",
" ToTensor()\n",
" Resize(size=(32, 32), interpolation=bicubic, max_size=None, antialias=True)\n",
" RandomHorizontalFlip(p=0.5)\n",
" Lambda()\n",
" )\n"
]
}
],
"source": [
"dataset = get_dataset(dataset_name='Flowers')\n",
"print(dataset)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Visualize Dataset"
]
},
{
"cell_type": "code",
2024-04-09 10:14:05 +02:00
"execution_count": 87,
2024-04-01 12:38:50 +02:00
"metadata": {},
"outputs": [],
"source": [
"loader = get_dataloader(\n",
" dataset_name=BaseConfig.DATASET,\n",
" batch_size=128,\n",
" device='cpu'\n",
")"
]
},
{
"cell_type": "code",
2024-04-09 10:14:05 +02:00
"execution_count": 88,
2024-04-01 12:38:50 +02:00
"metadata": {},
"outputs": [
{
"data": {
2024-04-09 10:14:05 +02:00
"image/png": "iVBORw0KGgoAAAANSUhEUgAAA64AAAHiCAYAAADoA5FMAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjguMywgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/H5lhTAAAACXBIWXMAAA9hAAAPYQGoP6dpAAEAAElEQVR4nOz9WaxsaZbfh/3WN+whpjPfIe+QNzNryKyhu9hNdjdN0yRF06JEE2q9GBBgk4Zt2JRNwRAMy4Ag2DDgFmw9GrQtQLBpAQQhSoIINSVDpkRIHNxwd5PdVV1jZuWcdzz3jDHt4Zv88O2Ic+6taqrryf1wViHqnBsZEWfH3t9e3/qv9V//JSmlxI3d2I3d2I3d2I3d2I3d2I3d2I3d2B9SU///PoAbu7Ebu7Ebu7Ebu7Ebu7Ebu7Ebu7F/mt0A1xu7sRu7sRu7sRu7sRu7sRu7sRv7Q203wPXGbuzGbuzGbuzGbuzGbuzGbuzG/lDbDXC9sRu7sRu7sRu7sRu7sRu7sRu7sT/UdgNcb+zGbuzGbuzGbuzGbuzGbuzGbuwPtd0A1xu7sRu7sRu7sRu7sRu7sRu7sRv7Q203wPXGbuzGbuzGbuzGbuzGbuzGbuzG/lDbDXC9sRu7sRu7sRu7sRu7sRu7sRu7sT/UdgNcb+zGbuzGbuzGbuzGbuzGbuzGbuwPtd0A1xu7sRu7sRu7sRu7sRu7sRu7sRv7Q23mZ3lx16yZH79AiUeJx1Ch0BgKBIEEKUZSiEQSMXra9SVJAlJEtB2hbYWtpyDQrs9w7YJ28QJjQRvQhUGURlQNqkT0GNEVoi1KWwQhpUB0c1zzAlEGEYOtj1CmRJkKYiSFQOw6kvcIBaBRyhJjJERP7xpc6Gn6FSF6fOjZP7rH7ftv893vfpcXL14gIgDEGBGR7b8BUkrb3zfPp5R+4vnNQyn1yu9aa0II28/evH/z36uqoixLQgiklNBa0/c9y+Vy+zkpJZRS7O3tsbu7y71792jblr7vaZqGlBKj0YiiKKiq6pVjXXSB3/hiiY+b45XNQf++118P/2n7DVP+Pb3+wp944qdYjJASaP0HePFPs2t/ZHPO03A0KXFrYvmj96d89vnHfPH4M5QSRMBYBZK/ZoqJNHwHAZRVKKUx2pKG/0Wfr09dlyglaC14Fwg+QBJEFNaUpJQIIYCk/NiczyiISogkwAMx/82UcD4RU8SHiDIKEfA+5OOKiRQhBjCloHT+rJQgeUhJIAlf+tK7TCc7/MZv/Abr9fqV9bcx+Ylrem2NAloJpVHbY+5DJMRETPkZUTAdjxiPRtRVjVKCcx0+OFrf4X0+H6Efjjl/QQC0VmilUCIgbM93AnwIhBAJMW6PW0TQShDyGo8pMZlM+GO//Cs8e37Md7//A+T69xBFUhWkmE8MeV3lPyckEUCRRAEKREhi8gJQhrIoqKuKdRvxPjEdJbRWJF2Skiclx2F9Qm3XBK+IKRFixFhFUSgKo1EiuN7n747gYySkiJb8va0SUkw459Eq30dJCUnAx/xtRMHu3peYzR7x6fOOVRtfvWLbNf5T1v9wJdPwfIz5DKcYQRJCwigH4klpDkkBlpRqEpYYFZAwKqIlYlQiRkUCJmaNVT22WCOSUAJn60PW/YR8hJFIS0wdMbYoGQPFcMyeGJak6IjR4V2PVopvfePnQRIvTp5ur3lIEBMk54gh4HtHIZpCaVRdkUSYzxu8c/h+TTUyVCMDLUSXWK8cfYyso6e2ltpaql2NsQoVCogQQ8COdijqKbYwpJRYrRa0Xc9yveJgd5ed6YSu7+i6jmdPX+R7OsV8bAz7W0rEGJlNJ9y+dch4PKIsSmK6umbWWMqqYvXBB3QvXrAe/LgJkVIpam1YlIq1hsduTRAYlzUxbvwBKEmMWiiDsOcFtCIZxTPtWBBx0aEQarHsR8WtpPBK4xR8QQtKMa7G7EfDYTSIDwB0dUkclcTDCZFAIKAlDj5RE2Kkc33eZxSYyw7desqzFc4oltOSi9CxjJ533/k61pR8/3vfR0QY1ePh3vtJv/MTnmmz5ZB9s4jkpzbvS2n7nsSV7wBQwrD/XPnwn/B9P+ELX7uH5PWnX319jIn1esVkMuHdd9/lybNP+PyLH6MH99F1kZSyr4oxEYZFIgJKXX10jHmvGY0M2qjNgZNiRCkQlYhRiJHtw3vJWwmg6xliavToPtE1+NUxuj5AF1Pc6iXBrXCrl9nvka+ZCOhyBCKEvtkejDIVogp0MUYpgzIVKXYkv+JLb73J3u6M3/32/5fVeoXRlrosmYxHFCZiNIgqAU2UEqV0jmVU9rcpCSFGehfo+oauW9N1K0Jw20uqlAznO23fX5U1WisKu7n+ia6POB9p2o4QA9674W3XFkEa1owa9pjhp+TFRIr5Po3DvqmVpapHvPveNzk/P+OD97+X97mYtw9IyHDdfYwMR5PX2mbJDOt0s7Ty90qEkNdf3MSACbTRiCiUvgqzRUWUJOpKMEZT1TVKF2hT4l1HiB7nHDEkXB8I3uO9Q+l87oyp83dLCWIgJU+uPwkpKWLKfu7hw0e8+egtPn56ymLdIdoiooZHjltyTCSo4Tklalg78tp/A3Ut/h1O79X3v36bvxYQXr83N484xF2bvTSlRNj42Gv+Nb8+kmIY9vfNz/ycEvjKo/t07Zp/8rv/eIidruK6jSm1XXLD8QraKpQCbUHphDZpe1+noEhRhkf+k67Pn2mMymu1tKQoxMT2XGmjSCniekeM+XuWZYHWmrIo8d6zXjV0vcvxwuDfMqbJr1dKtg8QYozcvnOHb3z9G3z88Yc8ffpke4KVzr/m85kvgtEaJQpt9HBhru4HYywMMZUarr8WEEl03ZqYAhEHUSAKLgRCTHQu72vGmLwenUOGeNoWajhOQemE6PwdRGlG07toU6HtlHZ1Qrt4QYp+uKZCCAnXeZTO5+7nv/lHONg/5A9iPxNwnR+/4Hf+s1+n1JeUZskOb1ClCZN0iEIjCXzTEdqONnm6fsWTj/4x0TSo/Y7xwZvUu/c5fPProBWff/KPOH/6ezz57t9hZw/GE2F0OMWUI6R4gCrvoMdfwYzfwNQHFKNdlFIk17E+/zaXX/w62s5Qdsr+m/8sxfgO1fQNYt8T1iu6F88I8wWaI7SMsMUeXd/RNEuOLz/jcn3CZyc/ZtXNmS9P+JP/3L/Er/4P/zX+2l/7a/z6r/96/lsp4ZxDa43W2dEC9H2/BY6bh3OOGPNFFpFX3lMUBcYYjDEURcFkMqFpGpqmwRiTg7cQtq+9d+8et2/fZr1eE2OkrmvOzs744Q9/uP1c5xx1XfMrv/Ir/NIv/RJ/6S/9JU5OTjg+PuaLL74gxshbb73F/v4+Dx48eCWQ+Oyi41/6Dz7ksot5gcsAXEQPjujVXV0EKpM3KB/ZOig/BJwMiQvZvCelvA2I8KonI3uzzuUduq6y300bsPfa61+x6x5yAL7p2s8Y8u++5y+8d8Df/svf4D/5T/8j/vq/+3+jqBSmECZ7FqVBKwh9IngIKYESRjslRVkzHu8SCcQUaZcNRmsePrhHWWmqkWZxvmS9bMEbjCo42LmD9471ekXSgaQiSmlIQnQKbQK2cEhcQeoJ5E35ctHTdI5l21FMCnShuLxc4Z0ndI7QCr4RJkeKcqygV0QndHOBIBA0//q//m/x3rvf4l/+K3+Fjz76KIPG18/a4Li214Yrx14oqAvN7Wm53YVOlj2NC7Q+oEQorPC1L3+Jd995mwdv3KOsCs7OnzJv5zy5fMbicsVq0dCcBnwb6ZwfNu/IpC4ZlwVFYRERXIRIIpBYrNasmpZl0+OH+6bQmrqwmOGe6nzgva99jf/k7/4X/L3/6u/zV/6V/9V2PZICqIJYPoDYImFOCj2kgNHD2hNNVCVRVSRVkMSS7Bh0AcWU20dHPLx3l08eOxbLwDfe8VRVQapv4cISHy74s2/957w5+5Rmael9ZOE69nYtBwcFh9MppdacnyxwPtFFxcp1rFxHbUpKZdgrC7zrmZ/PqS3UFmJpCKKY9woUWAu/9Mf/Db7xrb/K3/mNc378uH3ldsmb0zWAv73
2024-04-01 12:38:50 +02:00
"text/plain": [
"<Figure size 1200x600 with 1 Axes>"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"plt.figure(figsize=(12, 6), facecolor='white')\n",
"\n",
"for b_image, _ in loader:\n",
" b_image = inverse_transform(b_image).cpu()\n",
" grid_img = make_grid(b_image / 255.0, \n",
" nrow = 16, \n",
" padding=True,\n",
" pad_value=1,\n",
" normalize=True \n",
" )\n",
" plt.imshow(grid_img.permute(1, 2, 0))\n",
" plt.axis(\"off\")\n",
" break"
]
2024-04-09 10:14:05 +02:00
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## UNet Model"
]
},
{
"cell_type": "code",
"execution_count": 89,
"metadata": {},
"outputs": [],
"source": [
"### Architecture"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Architecture\n",
"\n",
"Comprises 5 components\n",
"\n",
"1. Encoder\n",
"2. Bottleneck\n",
"3. Decoder\n",
"4. Self-attention\n",
"5. Sinusoidal time embeddings\n",
"\n",
"### Details\n",
"\n",
"1. There are four levels in the encoder and decoder path with bottleneck blocks between them\n",
"2. Each encoder stage comprises two residual blocks with convolutional downsampling except the last level\n",
"3. Each corresponding decoder stage comprises three residual blocks and uses 2x nearest neighbors with convolutions to upsample the input from the previous level.\n",
"4. Each stage in the encoder path is connected to the decoder path with the help of skip connections\n",
"5. The model uses \"Self-Attention\" modules at a single feature map resolution\n",
"6. Every residual block in the model gets the inputs from the previous layer (and others in the decoder path) and the embedding of the current timestep. The timestep embedding informs the model of the input's current position in the Markov chain.\n",
"\n",
"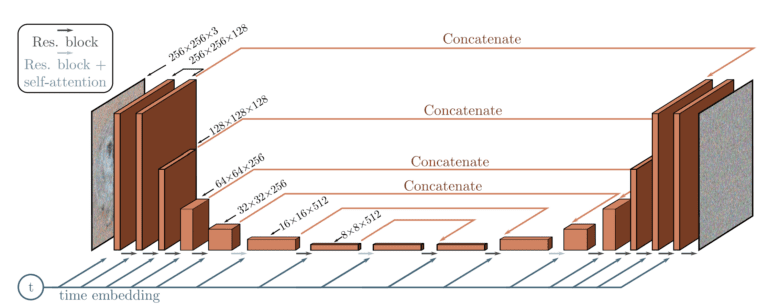"
]
},
{
"cell_type": "code",
"execution_count": 90,
"metadata": {},
"outputs": [],
"source": [
"class SinusoidalPositionEmbeddings(nn.Module):\n",
" def __init__(self, total_time_steps=1000, time_emb_dims=128, time_emb_dims_exp=512):\n",
" super().__init__()\n",
"\n",
" half_dim = time_emb_dims // 2 # half_dim=64\n",
"\n",
" emb = math.log(10000) / (half_dim - 1) # log_e(10000) = 9.21 / 63 =0.14619 000\n",
" emb = torch.exp(torch.arange(half_dim, dtype=torch.float32) * -emb)\n",
"\n",
" ts = torch.arange(total_time_steps, dtype=torch.float32) \n",
"\n",
" emb = torch.unsqueeze(ts, dim=-1) * torch.unsqueeze(emb, dim=0)\n",
" emb = torch.cat((emb.sin(), emb.cos()), dim=-1)\n",
"\n",
" self.time_blocks = nn.Sequential(\n",
" nn.Embedding.from_pretrained(emb),\n",
" nn.Linear(in_features=time_emb_dims, out_features=time_emb_dims_exp),\n",
" nn.SiLU(),\n",
" nn.Linear(in_features=time_emb_dims_exp, out_features=time_emb_dims_exp),\n",
" )\n",
"\n",
" def forward(self, time):\n",
" return self.time_blocks(time)"
]
},
{
"cell_type": "code",
"execution_count": 91,
"metadata": {},
"outputs": [],
"source": [
"class AttentionBlock(nn.Module):\n",
" def __init__(self, channels=64):\n",
" super().__init__()\n",
" self.channels = channels\n",
" self.group_norm = nn.GroupNorm(num_groups=8, num_channels=channels)\n",
" self.mhsa = nn.MultiheadAttention(embed_dim=self.channels, num_heads=4, batch_first=True)\n",
"\n",
" def forward(self, x):\n",
" B, _, H, W = x.shape\n",
" h = self.group_norm(x)\n",
" h = h.reshape(B, self.channels, H * W).swapaxes(1, 2)\n",
" h, _ = self.mhsa(h,h,h)\n",
" h = h.swapaxes(2, 1).view(B, self.channels, H, W)\n",
" return x + h"
]
},
{
"cell_type": "code",
"execution_count": 92,
"metadata": {},
"outputs": [],
"source": [
"class ResnetBlock(nn.Module):\n",
" def __init__(self, *, in_channels, out_channels, dropout_rate=0.1, time_emb_dims=512, apply_attention=False):\n",
" super().__init__()\n",
" self.in_channels = in_channels\n",
" self.out_channels = out_channels\n",
"\n",
" self.act_fn = nn.SiLU()\n",
"\n",
" # Group1\n",
" self.normlize_1 = nn.GroupNorm(num_groups=8, num_channels=self.in_channels)\n",
" self.conv_1 = nn.Conv2d(in_channels=self.in_channels, out_channels=self.out_channels, kernel_size=3, stride=1, padding=\"same\")\n",
"\n",
" # Group2 time embedding\n",
" self.dense_1 = nn.Linear(in_features=time_emb_dims, out_features=self.out_channels)\n",
"\n",
" # Group3 \n",
" self.normlize_2 = nn.GroupNorm(num_groups=8, num_channels=out_channels)\n",
" self.dropout = nn.Dropout2d(p=dropout_rate)\n",
" self.conv_2 = nn.Conv2d(in_channels=self.out_channels, out_channels=self.out_channels, kernel_size=3, stride=1, padding=\"same\")\n",
"\n",
" if self.in_channels != self.out_channels:\n",
" self.match_input = nn.Conv2d(in_channels=self.in_channels,out_channels=self.out_channels, kernel_size=1, stride=1)\n",
" else:\n",
" self.attention = nn.Identity()\n",
" \n",
" if apply_attention:\n",
" self.attention = AttentionBlock(channels=self.out_channels)\n",
" else:\n",
" self.attention = nn.Identity()\n",
" def forward(self, x, t):\n",
" #group 1\n",
" h = self.act_fn(self.normlize_1(x))\n",
" h = self.conv_1(h)\n",
"\n",
" #group 2\n",
" # add in timestep embedding\n",
" h += self.dense_1(self.act_fn(t))[:, :, None, None]\n",
"\n",
" #group 3\n",
" h = self.act_fn(self.normlize_2(h))\n",
" h = self.dropout(h)\n",
" h = self.conv_2(h)\n",
"\n",
" # Residual and attention\n",
" h = h + self.match_input(x)\n",
" h = self.attention(h)\n",
"\n",
" return h"
]
},
{
"cell_type": "code",
"execution_count": 93,
"metadata": {},
"outputs": [],
"source": [
"class DownSample(nn.Module):\n",
" def __init__(self, channels):\n",
" super().__init__()\n",
" self.downsample = nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=3, stride=2, padding=1)\n",
"\n",
" def forward(self, x, *args):\n",
" return self.downsample(x)"
]
},
{
"cell_type": "code",
"execution_count": 94,
"metadata": {},
"outputs": [],
"source": [
"class UpSample(nn.Module):\n",
" def __init__(self, in_channels):\n",
" super().__init__()\n",
"\n",
" self.upsample = nn.Sequential(\n",
" nn.Upsample(scale_factor=2, mode=\"nearest\"),\n",
" nn.Conv2d(in_channels=in_channels, out_channels=in_channels, kernel_size=3, stride=1, padding=1),\n",
" )\n",
"\n",
" def forward(self, x, *args):\n",
" return self.upsample(x)"
]
},
{
"cell_type": "code",
"execution_count": 95,
"metadata": {},
"outputs": [],
"source": [
"class UNet(nn.Module):\n",
" def __init__(\n",
" self,\n",
" input_channels=3,\n",
" output_channels=3,\n",
" num_res_blocks=2,\n",
" base_channels=128,\n",
" base_channels_multiples=(1,2,4,8),\n",
" apply_attention=(False,False,True,False),\n",
" dropout_rate=0.1,\n",
" time_multiple=4,\n",
" ):\n",
" super().__init__()\n",
"\n",
" time_emb_dims_exp = base_channels * time_multiple\n",
" self.time_embeddings = SinusoidalPositionEmbeddings(time_emb_dims=base_channels, time_emb_dims_exp=time_emb_dims_exp)\n",
"\n",
" self.first = nn.Conv2d(in_channels=input_channels, out_channels=base_channels, kernel_size=3, stride=1, padding=\"same\")\n",
"\n",
" num_resolutions = len(base_channels_multiples)\n",
"\n",
2024-07-09 14:20:03 +02:00
" # encoder blocks = resnetblock * 3 + \n",
2024-04-09 10:14:05 +02:00
" self.encoder_blocks = nn.ModuleList()\n",
" curr_channels = [base_channels]\n",
" in_channels = base_channels\n",
"\n",
" for level in range(num_resolutions):\n",
" out_channels = base_channels * base_channels_multiples[level]\n",
"\n",
" for _ in range(num_res_blocks):\n",
"\n",
" block = ResnetBlock(\n",
" in_channels = in_channels,\n",
" out_channels=out_channels,\n",
" dropout_rate=dropout_rate,\n",
" time_emb_dims=time_emb_dims_exp,\n",
" apply_attention=apply_attention[level],\n",
" )\n",
" self.encoder_blocks.append(block)\n",
"\n",
" in_channels = out_channels\n",
" curr_channels.append(in_channels)\n",
"\n",
" if level != (num_resolutions - 1):\n",
" self.encoder_blocks.append(DownSample(channels=in_channels))\n",
" curr_channels.append(in_channels)\n",
"\n",
" self.bottleneck_blocks = nn.ModuleList(\n",
" (\n",
" ResnetBlock(\n",
" in_channels=in_channels,\n",
" out_channels=in_channels,\n",
" dropout_rate=dropout_rate,\n",
" time_emb_dims=time_emb_dims_exp,\n",
" apply_attention=True,\n",
" ),\n",
" ResnetBlock(\n",
" in_channels=in_channels,\n",
" out_channels=in_channels,\n",
" dropout_rate=dropout_rate,\n",
" time_emb_dims=time_emb_dims_exp,\n",
" apply_attention=False,\n",
" ),\n",
" )\n",
" )\n",
"\n",
" self.decoder_blocks = nn.ModuleList()\n",
"\n",
" for level in reversed(range(num_resolutions)):\n",
" out_channels = base_channels * base_channels_multiples[level]\n",
"\n",
" for _ in range(num_res_blocks + 1):\n",
" encoder_in_channels = curr_channels.pop()\n",
" block = ResnetBlock(\n",
" in_channels=encoder_in_channels + in_channels,\n",
" out_channels=out_channels,\n",
" dropout_rate=dropout_rate,\n",
" time_emb_dims=time_emb_dims_exp,\n",
" apply_attention=apply_attention[level]\n",
" )\n",
"\n",
" in_channels = out_channels\n",
" self.decoder_blocks.append(block)\n",
" \n",
" if level != 0:\n",
" self.decoder_blocks.append(UpSample(in_channels))\n",
"\n",
" self.final = nn.Sequential(\n",
" nn.GroupNorm(num_groups=8, num_channels=in_channels),\n",
" nn.SiLU(),\n",
" nn.Conv2d(in_channels=in_channels, out_channels=output_channels, kernel_size=3, stride=1, padding=\"same\"),\n",
" )\n",
"\n",
" def forward(self, x, t):\n",
"\n",
" time_emb = self.time_embeddings(t)\n",
"\n",
" h = self.first(x)\n",
" outs = [h]\n",
"\n",
" for layer in self.encoder_blocks:\n",
" h = layer(h, time_emb)\n",
" outs.append(h)\n",
"\n",
" for layer in self.bottleneck_blocks:\n",
" h = layer(h, time_emb)\n",
"\n",
" for layer in self.decoder_blocks:\n",
" if isinstance(layer, ResnetBlock):\n",
" out = outs.pop()\n",
" h = torch.cat([h, out], dim=1)\n",
" h = layer(h, time_emb)\n",
"\n",
" h = self.final(h)\n",
"\n",
" return h\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Diffusion Process"
]
},
{
"cell_type": "code",
"execution_count": 96,
"metadata": {},
"outputs": [],
"source": [
"class SimpleDiffusion:\n",
" def __init__(\n",
" self,\n",
" num_diffusion_timesteps=1000,\n",
" img_shape=(3, 64, 64),\n",
" device=\"cpu\"\n",
" ):\n",
" self.num_diffusion_timesteps = num_diffusion_timesteps\n",
" self.img_shape = img_shape\n",
" self.device=device\n",
"\n",
" self.initialize()\n",
"\n",
" def initialize(self):\n",
" self.beta = self.get_betas()\n",
" self.alpha = 1 - self.beta\n",
"\n",
" self.sqrt_beta = torch.sqrt(self.beta)\n",
" self.alpha_cumulative = torch.cumprod(self.alpha, dim=0)\n",
" self.sqrt_alpha_cumulative = torch.sqrt(self.alpha_cumulative)\n",
" self.one_by_sqrt_alpha = 1. / torch.sqrt(self.alpha)\n",
" self.sqrt_one_minus_alpha_cumulative = torch.sqrt(1-self.alpha_cumulative)\n",
"\n",
" def get_betas(self):\n",
2024-07-09 14:20:03 +02:00
" \"\"\"linear schedule, proposed in original ddpm paper 线性在原ddpm论文中提出\"\"\"\n",
2024-04-09 10:14:05 +02:00
" scale = 1000 / self.num_diffusion_timesteps\n",
" beta_start = scale * 1e-4\n",
" beta_end = scale * 0.02\n",
" return torch.linspace(\n",
" beta_start,\n",
" beta_end,\n",
" self.num_diffusion_timesteps,\n",
" dtype=torch.float32,\n",
" device=self.device,\n",
" )\n",
"\n",
"def forward_diffusion(sd: SimpleDiffusion, x0: torch.Tensor, timesteps: torch.Tensor):\n",
" eps = torch.randn_like(x0) #Noise\n",
" mean = get(sd.sqrt_alpha_cumulative, t=timesteps) * x0 # Image scaled\n",
" std_dev = get(sd.sqrt_one_minus_alpha_cumulative, t=timesteps) # Noise scaled\n",
" sample = mean + std_dev * eps # scaled inputs * scaled noise\n",
"\n",
" return sample, eps # return ... gt noise --> model predicts this)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Sample Forward Diffusion Process"
]
},
{
"cell_type": "code",
"execution_count": 97,
"metadata": {},
"outputs": [],
"source": [
"sd = SimpleDiffusion(num_diffusion_timesteps=TrainingConfig.TIMESTEPS, device=\"cpu\")\n",
"\n",
"loader = iter( # converting dataloader into an iterator for now.\n",
" get_dataloader(\n",
" dataset_name=BaseConfig.DATASET,\n",
" batch_size=6,\n",
" device=\"cpu\",\n",
" )\n",
")"
]
},
{
"cell_type": "code",
"execution_count": 98,
"metadata": {},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAxoAAAF+CAYAAAAFumw3AAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjguMywgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/H5lhTAAAACXBIWXMAAA9hAAAPYQGoP6dpAAEAAElEQVR4nOzdd5gV1f348feUO7ffu71Xlt2FXTqIgCA2xN5rjBqNJTFqLOnV9GK6JqaYr0mIxhhL7AUFBekgvbO999vblPP7Y3V/IZp8WYMxfjOv59nn4Z4zd+6Zzz0zzOfOOTOSEEJgs9lsNpvNZrPZbEeR/H43wGaz2Ww2m81ms/3fYycaNpvNZrPZbDab7aizEw2bzWaz2Ww2m8121NmJhs1ms9lsNpvNZjvq7ETDZrPZbDabzWazHXV2omGz2Ww2m81ms9mOOjvRsNlsNpvNZrPZbEednWjYbDabzWaz2Wy2o85ONGw2m81ms9lsNttRZycaNpvNdhS9+uqrSJLEq6++etTXfddddyFJ0mFlhmHwmc98hvLycmRZ5rzzzgMgFotx3XXXUVRUhCRJ3HbbbUe9PVVVVXzkIx856uu12Ww22/8NdqJhs9neE7/73e+QJOkd/z73uc+938173/19fFwuFyUlJSxdupSf/exnRKPRI1rP//zP/3D33Xdz0UUX8fvf/57bb78dgG9/+9v87ne/4+Mf/zjLli3jyiuvfC8359/qnWJXV1fHzTffTF9f3/vdPJvNZrO9SX2/G2Cz2f5v+/rXv051dfVhZVOmTHmfWvOf56346LpOb28vr776Krfddhs/+tGPeOqpp5g2bdrYsl/60pfelqStWLGC0tJSfvzjH7+tfN68eXz1q199z9q+f/9+ZPn9+73qrdilUilef/117rvvPp577jl27dqFx+N539pls9lstlF2omGz2d5Tp59+OnPmzDnq643H43i93qO+3v+NEIJUKoXb7T4q6/v7+Hz+859nxYoVnHXWWZxzzjns3bt37LNUVUVVDz9s9/f3k5WV9bb19vf309DQcFTa+I84nc73dP3/m7+N3XXXXUdubi4/+tGPePLJJ7n88svf8T3vV7+x2Wy2/0b20Cmbzfa+WrFiBYsWLcLr9ZKVlcW5557L3r17D1vmrbkJe/bs4UMf+hDZ2dksXLiQp556CkmS2LFjx9iyjz32GJIkccEFFxy2jsmTJ3PppZeOvX7ggQc46aSTKCgowOl00tDQwH333fe29lVVVXHWWWfx4osvMmfOHNxuN7/61a8A6Ozs5LzzzsPr9VJQUMDtt99OOp3+l2Ny0kkn8eUvf5m2tjb++Mc/vi0OAK2trUiSxMqVK9m9e/fYMKK35oi0tLTw7LPPjpW3traODTlqbW097PPeaV7JwYMHufDCCykqKsLlclFWVsZll11GOBw+LDZ/P0ejubmZiy++mJycHDweD/PmzePZZ599x8975JFH+Na3vkVZWRkul4uTTz6ZQ4cO/UtxA2hpaQHgIx/5CD6fj6amJs444wz8fj9XXHEFMJpw3HnnnZSXl+N0Oqmvr+cHP/gBQoi3rfePf/wjc+fOxePxkJ2dzfHHH89LL7102DLPP//8WD/2+/2ceeaZ7N69+7Blent7ueaaaygrK8PpdFJcXMy555572PexefNmli5dSl5eHm63m+rqaq699tp3HRObzWZ7P9lXNGw223sqHA4zODh4WFleXh4AL7/8MqeffjoTJkzgrrvuIplMcs8993DcccfxxhtvUFVVddj7Lr74Ympra/n2t7+NEIKFCxciSRKrVq0aG2K0evVqZFnm9ddfH3vfwMAA+/bt4+abbx4ru++++2hsbOScc85BVVWefvppbrrpJizL4hOf+MRhn7t//34uv/xybrzxRq6//nrq6+tJJpOcfPLJtLe3c+utt1JSUsKyZctYsWLFUYnblVdeyRe+8AVeeuklrr/++rfV5+fns2zZMr71rW8Ri8X4zne+A4wmVMuWLeP222+nrKyMO++8c2z5I5XJZFi6dCnpdJpbbrmFoqIiurq6eOaZZwiFQgSDwXd8X19fHwsWLCCRSHDrrbeSm5vL73//e8455xweffRRzj///MOW/+53v4ssy3zqU58iHA7z/e9/nyuuuIINGzYccVv/VlNTEwC5ubljZYZhsHTpUhYuXMgPfvADPB4PQgjOOeccVq5cyUc/+lFmzJjBiy++yKc//Wm6uroOG4b2ta99jbvuuosFCxbw9a9/HU3T2LBhAytWrODUU08FYNmyZVx99dUsXbqU733veyQSCe677z4WLlzI1q1bx/rxhRdeyO7du7nllluoqqqiv7+f5cuX097ePvb61FNPJT8/n8997nNkZWXR2trK448//q7iYbPZbO87YbPZbO+BBx54QADv+PeWGTNmiIKCAjE0NDRWtn37diHLsrjqqqvGyr761a8KQFx++eVv+5zGxkZxySWXjL2eNWuWuPjiiwUg9u7dK4QQ4vHHHxeA2L59+9hyiUTibetaunSpmDBhwmFllZWVAhAvvPDCYeU/+clPBCAeeeSRsbJ4PC4mTpwoALFy5cojis+mTZv+4TLBYFDMnDlz7PVbcfhbixcvFo2NjW97b2VlpTjzzDPf8TNbWloOK1+5cuVhbd66dasAxF/+8pd/ug2VlZXi6quvHnt92223CUCsXr16rCwajYrq6mpRVVUlTNM87PMmT54s0un02LI//elPBSB27tz5Tz/3re14+eWXxcDAgOjo6BAPP/ywyM3NFW63W3R2dgohhLj66qsFID73uc8d9v6//vWvAhDf/OY3Dyu/6KKLhCRJ4tChQ0IIIQ4ePChkWRbnn3/+WNvfYlnW2PZlZWWJ66+//rD63t5eEQwGx8pHRkYEIO6+++5/uF1PPPHE/9onbDab7YPEHjpls9neUz//+c9Zvnz5YX8APT09bNu2jY985CPk5OSMLT9t2jSWLFnCc88997Z1fexjH3tb2aJFi1i9ejUA0WiU7du3c8MNN5CXlzdWvnr1arKysg6bhP63cyzeuuqyePFimpubDxseBFBdXc3SpUsPK3vuuecoLi7moosuGivzeDzccMMNRxyb/43P5zviu08dTW9dsXjxxRdJJBJH/L7nnnuOuXPnsnDhwrEyn8/HDTfcQGtrK3v27Dls+WuuuQZN08ZeL1q0CBgdfnUkTjnlFPLz8ykvL+eyyy7D5/PxxBNPUFpaethyH//4x9/WTkVRuPXWWw8rv/POOxFC8PzzzwPw17/+Fcuy+MpXvvK2Se9vDWFbvnw5oVCIyy+/nMHBwbE/RVE49thjWblyJTDa3zRN49VXX2VkZOQdt+etuTbPPPMMuq4fUQxsNpvtP5mdaNhstvfU3LlzOeWUUw77A2hrawOgvr7+be+ZPHkyg4ODxOPxw8r//u5VMHpy2tPTw6FDh1i7di2SJDF//vzDEpDVq1dz3HHHHXayuGbNGk455ZSxuSH5+fl84QtfAHjHROPvtbW1MXHixLc91+KdtufdisVi+P3+o7a+I1VdXc0dd9zB/fffT15eHkuXLuXnP//52+Ly99ra2v7h9/lW/d+qqKg47HV2djbAPzwR/3tvJbErV65kz549NDc3vy0hVFWVsrKyt7WzpKTkbbH9+3Y2NTUhy/I/nVR/8OBBYHR+SH5+/mF/L730Ev39/cDoxPnvfe97PP/88xQWFnL88cfz/e9/n97e3rF1LV68mAsvvJCvfe1r5OXlce655/LAAw8clXk/NpvN9n6wEw2bzfaB8U53enrr1/NVq1axevVqZs2ahdfrHUs0YrEYW7duHfu1HEZPIE8++WQGBwf50Y9+xLPPPsvy5cvHnkFhWdb/+rnvtc7OTsLhMBMnTjxq6/z7pOgtpmm+reyHP/whO3bs4Atf+ALJZJJbb72VxsZGOjs7j1p7FEV5x3LxDhOy38lbSewJJ5zA5MmT3/FWu06n8z29Be9bfWXZsmVvu3K3fPlynnzyybFlb7vtNg4cOMB3vvMdXC4XX/7yl5k8eTJbt24FRr+fRx99lHXr1nHzzTfT1dXFtddey+z
"text/plain": [
"<Figure size 1000x500 with 12 Axes>"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"x0s, _ = next(loader)\n",
"\n",
"noisy_images = []\n",
"specific_timesteps = [0, 10, 50, 100, 150, 200, 250, 300, 400, 600, 800, 999]\n",
"\n",
"for timestep in specific_timesteps:\n",
" timestep = torch.as_tensor(timestep, dtype=torch.long)\n",
"\n",
" xts, _ = forward_diffusion(sd, x0s, timestep)\n",
" xts = inverse_transform(xts) / 255.0\n",
" xts = make_grid(xts, nrow=1, padding=1)\n",
"\n",
" noisy_images.append(xts)\n",
"\n",
"# Plot and see samples at different timesteps\n",
"\n",
"_, ax = plt.subplots(1, len(noisy_images), figsize=(10, 5), facecolor=\"white\")\n",
"\n",
"for i, (timestep, noisy_sample) in enumerate(zip(specific_timesteps, noisy_images)):\n",
" ax[i].imshow(noisy_sample.squeeze(0).permute(1, 2, 0))\n",
" ax[i].set_title(f\"t={timestep}\", fontsize=8)\n",
" ax[i].axis(\"off\")\n",
" ax[i].grid(False)\n",
"\n",
"plt.suptitle(\"Forward Diffusion Process\", y=0.9)\n",
"plt.axis(\"off\")\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Training"
]
},
{
"cell_type": "code",
"execution_count": 101,
"metadata": {},
"outputs": [],
"source": [
"@dataclass\n",
"class ModelConfig:\n",
" BASE_CH = 64 # 64, 128, 256, 256\n",
" BASE_CH_MULT = (1, 2, 4, 4) # 32, 16, 8, 8 \n",
" APPLY_ATTENTION = (False, True, True, False)\n",
" DROPOUT_RATE = 0.1\n",
" TIME_EMB_MULT = 4 # 128"
]
},
{
"cell_type": "code",
"execution_count": 102,
"metadata": {},
"outputs": [],
"source": [
"model = UNet(\n",
" input_channels = TrainingConfig.IMG_SHAPE[0],\n",
" output_channels = TrainingConfig.IMG_SHAPE[0],\n",
" base_channels = ModelConfig.BASE_CH,\n",
" base_channels_multiples = ModelConfig.BASE_CH_MULT,\n",
" apply_attention = ModelConfig.APPLY_ATTENTION,\n",
" dropout_rate = ModelConfig.DROPOUT_RATE,\n",
" time_multiple = ModelConfig.TIME_EMB_MULT,\n",
")\n",
"model.to(BaseConfig.DEVICE)\n",
"\n",
"optimizer = torch.optim.AdamW(model.parameters(), lr=TrainingConfig.LR)\n",
"\n",
"dataloader = get_dataloader(\n",
" dataset_name = BaseConfig.DATASET,\n",
" batch_size = TrainingConfig.BATCH_SIZE,\n",
" device = BaseConfig.DEVICE,\n",
" pin_memory = True,\n",
" num_workers = TrainingConfig.NUM_WORKERS,\n",
")\n",
"\n",
"loss_fn = nn.MSELoss()\n",
"\n",
"sd = SimpleDiffusion(\n",
" num_diffusion_timesteps = TrainingConfig.TIMESTEPS,\n",
" img_shape = TrainingConfig.IMG_SHAPE,\n",
" device = BaseConfig.DEVICE,\n",
")\n",
"\n",
"scaler = amp.GradScaler()"
]
},
{
"cell_type": "code",
"execution_count": 103,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Logging at: Logs_Checkpoints\\Inference\\version1\n",
"Model Checkpoint at: Logs_Checkpoints\\checkpoints\\version1\n"
]
}
],
"source": [
"total_epochs = TrainingConfig.NUM_EPOCHS + 1\n",
"log_dir, checkpoint_dir = setup_log_directory(config=BaseConfig())\n",
"\n",
"generate_video = False\n",
"ext = \".mp4\" if generate_video else \".png\""
]
},
{
"cell_type": "code",
"execution_count": 104,
"metadata": {},
"outputs": [],
"source": [
"# Algorithm 1: Training\n",
"\n",
"def train_one_epoch(model, sd, loader, optimizer, scaler, loss_fn, epoch=800, \n",
" base_config=BaseConfig(), training_config=TrainingConfig()):\n",
" \n",
" loss_record = MeanMetric()\n",
" model.train()\n",
"\n",
" with tqdm(total=len(loader), dynamic_ncols=True) as tq:\n",
" tq.set_description(f\"Train :: Epoch: {epoch}/{training_config.NUM_EPOCHS}\")\n",
" \n",
" for x0s, _ in loader:\n",
" tq.update(1)\n",
" \n",
2024-07-09 14:20:03 +02:00
" # 生成噪声\n",
2024-04-09 10:14:05 +02:00
" ts = torch.randint(low=1, high=training_config.TIMESTEPS, size=(x0s.shape[0],), device=base_config.DEVICE)\n",
" xts, gt_noise = forward_diffusion(sd, x0s, ts)\n",
"\n",
2024-07-09 14:20:03 +02:00
" # forward & get loss\n",
2024-04-09 10:14:05 +02:00
" with amp.autocast():\n",
" pred_noise = model(xts, ts)\n",
" loss = loss_fn(gt_noise, pred_noise)\n",
"\n",
2024-07-09 14:20:03 +02:00
" # 梯度缩放和反向传播\n",
2024-04-09 10:14:05 +02:00
" optimizer.zero_grad(set_to_none=True)\n",
" scaler.scale(loss).backward()\n",
"\n",
" # scaler.unscale_(optimizer)\n",
" # torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)\n",
"\n",
" scaler.step(optimizer)\n",
" scaler.update()\n",
"\n",
" loss_value = loss.detach().item()\n",
" loss_record.update(loss_value)\n",
"\n",
" tq.set_postfix_str(s=f\"Loss: {loss_value:.4f}\")\n",
"\n",
" mean_loss = loss_record.compute().item()\n",
" \n",
" tq.set_postfix_str(s=f\"Epoch Loss: {mean_loss:.4f}\")\n",
" \n",
" return mean_loss "
]
},
{
"cell_type": "code",
"execution_count": 105,
"metadata": {},
"outputs": [],
"source": [
"@torch.no_grad()\n",
"def reverse_diffusion(model, sd, timesteps=1000, img_shape=(3, 64, 64), \n",
" num_images=5, nrow=8, device=\"cpu\", **kwargs):\n",
"\n",
" x = torch.randn((num_images, *img_shape), device=device)\n",
" model.eval()\n",
"\n",
" if kwargs.get(\"generate_video\", False):\n",
" outs = []\n",
"\n",
" for time_step in tqdm(iterable=reversed(range(1, timesteps)), \n",
" total=timesteps-1, dynamic_ncols=False, \n",
" desc=\"Sampling :: \", position=0):\n",
"\n",
" ts = torch.ones(num_images, dtype=torch.long, device=device) * time_step\n",
" z = torch.randn_like(x) if time_step > 1 else torch.zeros_like(x)\n",
"\n",
" predicted_noise = model(x, ts)\n",
"\n",
" beta_t = get(sd.beta, ts)\n",
" one_by_sqrt_alpha_t = get(sd.one_by_sqrt_alpha, ts)\n",
" sqrt_one_minus_alpha_cumulative_t = get(sd.sqrt_one_minus_alpha_cumulative, ts) \n",
"\n",
" x = (\n",
" one_by_sqrt_alpha_t\n",
" * (x - (beta_t / sqrt_one_minus_alpha_cumulative_t) * predicted_noise)\n",
" + torch.sqrt(beta_t) * z\n",
" )\n",
"\n",
" if kwargs.get(\"generate_video\", False):\n",
" x_inv = inverse_transform(x).type(torch.uint8)\n",
" grid = make_grid(x_inv, nrow=nrow, pad_value=255.0).to(\"cpu\")\n",
" ndarr = torch.permute(grid, (1, 2, 0)).numpy()[:, :, ::-1]\n",
" outs.append(ndarr)\n",
"\n",
" if kwargs.get(\"generate_video\", False): # Generate and save video of the entire reverse process. \n",
" frames2vid(outs, kwargs['save_path'])\n",
" display(Image.fromarray(outs[-1][:, :, ::-1])) # Display the image at the final timestep of the reverse process.\n",
" return None\n",
"\n",
" else: # Display and save the image at the final timestep of the reverse process. \n",
" x = inverse_transform(x).type(torch.uint8)\n",
" grid = make_grid(x, nrow=nrow, pad_value=255.0).to(\"cpu\")\n",
" pil_image = TF.functional.to_pil_image(grid)\n",
" pil_image.save(kwargs['save_path'], format=save_path[-3:].upper())\n",
" display(pil_image)\n",
" return None"
]
},
{
"cell_type": "code",
"execution_count": 106,
"metadata": {},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"Train :: Epoch: 1/800: 0%| | 0/135 [00:00<?, ?it/s]\n"
]
},
{
"ename": "AttributeError",
"evalue": "Can't pickle local object 'get_dataset.<locals>.<lambda>'",
"output_type": "error",
"traceback": [
"\u001b[1;31m---------------------------------------------------------------------------\u001b[0m",
"\u001b[1;31mAttributeError\u001b[0m Traceback (most recent call last)",
"Cell \u001b[1;32mIn[106], line 6\u001b[0m\n\u001b[0;32m 3\u001b[0m gc\u001b[38;5;241m.\u001b[39mcollect()\n\u001b[0;32m 5\u001b[0m \u001b[38;5;66;03m# Algorithm 1: Training\u001b[39;00m\n\u001b[1;32m----> 6\u001b[0m \u001b[43mtrain_one_epoch\u001b[49m\u001b[43m(\u001b[49m\u001b[43mmodel\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43msd\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mdataloader\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43moptimizer\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mscaler\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mloss_fn\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mepoch\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mepoch\u001b[49m\u001b[43m)\u001b[49m\n\u001b[0;32m 8\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m epoch \u001b[38;5;241m%\u001b[39m \u001b[38;5;241m20\u001b[39m \u001b[38;5;241m==\u001b[39m \u001b[38;5;241m0\u001b[39m:\n\u001b[0;32m 9\u001b[0m save_path \u001b[38;5;241m=\u001b[39m os\u001b[38;5;241m.\u001b[39mpath\u001b[38;5;241m.\u001b[39mjoin(log_dir, \u001b[38;5;124mf\u001b[39m\u001b[38;5;124m\"\u001b[39m\u001b[38;5;132;01m{\u001b[39;00mepoch\u001b[38;5;132;01m}\u001b[39;00m\u001b[38;5;132;01m{\u001b[39;00mext\u001b[38;5;132;01m}\u001b[39;00m\u001b[38;5;124m\"\u001b[39m)\n",
"Cell \u001b[1;32mIn[104], line 12\u001b[0m, in \u001b[0;36mtrain_one_epoch\u001b[1;34m(model, sd, loader, optimizer, scaler, loss_fn, epoch, base_config, training_config)\u001b[0m\n\u001b[0;32m 9\u001b[0m \u001b[38;5;28;01mwith\u001b[39;00m tqdm(total\u001b[38;5;241m=\u001b[39m\u001b[38;5;28mlen\u001b[39m(loader), dynamic_ncols\u001b[38;5;241m=\u001b[39m\u001b[38;5;28;01mTrue\u001b[39;00m) \u001b[38;5;28;01mas\u001b[39;00m tq:\n\u001b[0;32m 10\u001b[0m tq\u001b[38;5;241m.\u001b[39mset_description(\u001b[38;5;124mf\u001b[39m\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mTrain :: Epoch: \u001b[39m\u001b[38;5;132;01m{\u001b[39;00mepoch\u001b[38;5;132;01m}\u001b[39;00m\u001b[38;5;124m/\u001b[39m\u001b[38;5;132;01m{\u001b[39;00mtraining_config\u001b[38;5;241m.\u001b[39mNUM_EPOCHS\u001b[38;5;132;01m}\u001b[39;00m\u001b[38;5;124m\"\u001b[39m)\n\u001b[1;32m---> 12\u001b[0m \u001b[43m \u001b[49m\u001b[38;5;28;43;01mfor\u001b[39;49;00m\u001b[43m \u001b[49m\u001b[43mx0s\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43m_\u001b[49m\u001b[43m \u001b[49m\u001b[38;5;129;43;01min\u001b[39;49;00m\u001b[43m \u001b[49m\u001b[43mloader\u001b[49m\u001b[43m:\u001b[49m\n\u001b[0;32m 13\u001b[0m \u001b[43m \u001b[49m\u001b[43mtq\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mupdate\u001b[49m\u001b[43m(\u001b[49m\u001b[38;5;241;43m1\u001b[39;49m\u001b[43m)\u001b[49m\n\u001b[0;32m 15\u001b[0m \u001b[43m \u001b[49m\u001b[43mts\u001b[49m\u001b[43m \u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43m \u001b[49m\u001b[43mtorch\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mrandint\u001b[49m\u001b[43m(\u001b[49m\u001b[43mlow\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[38;5;241;43m1\u001b[39;49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mhigh\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mtraining_config\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mTIMESTEPS\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43msize\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43m(\u001b[49m\u001b[43mx0s\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mshape\u001b[49m\u001b[43m[\u001b[49m\u001b[38;5;241;43m0\u001b[39;49m\u001b[43m]\u001b[49m\u001b[43m,\u001b[49m\u001b[43m)\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mdevice\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mbase_config\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mDEVICE\u001b[49m\u001b[43m)\u001b[49m\n",
"Cell \u001b[1;32mIn[73], line 12\u001b[0m, in \u001b[0;36mDeviceDataLoader.__iter__\u001b[1;34m(self)\u001b[0m\n\u001b[0;32m 10\u001b[0m \u001b[38;5;250m\u001b[39m\u001b[38;5;124;03m\"\"\"在移动到设备后生成一个批次的数据\"\"\"\u001b[39;00m\n\u001b[0;32m 11\u001b[0m \u001b[38;5;250m\u001b[39m\u001b[38;5;124;03m\"\"\"Yield a batch of data after moving it to device\"\"\"\u001b[39;00m\n\u001b[1;32m---> 12\u001b[0m \u001b[43m\u001b[49m\u001b[38;5;28;43;01mfor\u001b[39;49;00m\u001b[43m \u001b[49m\u001b[43mb\u001b[49m\u001b[43m \u001b[49m\u001b[38;5;129;43;01min\u001b[39;49;00m\u001b[43m \u001b[49m\u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mdl\u001b[49m\u001b[43m:\u001b[49m\n\u001b[0;32m 13\u001b[0m \u001b[43m \u001b[49m\u001b[38;5;28;43;01myield\u001b[39;49;00m\u001b[43m \u001b[49m\u001b[43mto_device\u001b[49m\u001b[43m(\u001b[49m\u001b[43mb\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mdevice\u001b[49m\u001b[43m)\u001b[49m\n",
"File \u001b[1;32mc:\\Users\\Cxyoz\\.conda\\py-133-pytorch\\Lib\\site-packages\\torch\\utils\\data\\dataloader.py:439\u001b[0m, in \u001b[0;36mDataLoader.__iter__\u001b[1;34m(self)\u001b[0m\n\u001b[0;32m 437\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39m_iterator\n\u001b[0;32m 438\u001b[0m \u001b[38;5;28;01melse\u001b[39;00m:\n\u001b[1;32m--> 439\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_get_iterator\u001b[49m\u001b[43m(\u001b[49m\u001b[43m)\u001b[49m\n",
"File \u001b[1;32mc:\\Users\\Cxyoz\\.conda\\py-133-pytorch\\Lib\\site-packages\\torch\\utils\\data\\dataloader.py:387\u001b[0m, in \u001b[0;36mDataLoader._get_iterator\u001b[1;34m(self)\u001b[0m\n\u001b[0;32m 385\u001b[0m \u001b[38;5;28;01melse\u001b[39;00m:\n\u001b[0;32m 386\u001b[0m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39mcheck_worker_number_rationality()\n\u001b[1;32m--> 387\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[43m_MultiProcessingDataLoaderIter\u001b[49m\u001b[43m(\u001b[49m\u001b[38;5;28;43mself\u001b[39;49m\u001b[43m)\u001b[49m\n",
"File \u001b[1;32mc:\\Users\\Cxyoz\\.conda\\py-133-pytorch\\Lib\\site-packages\\torch\\utils\\data\\dataloader.py:1040\u001b[0m, in \u001b[0;36m_MultiProcessingDataLoaderIter.__init__\u001b[1;34m(self, loader)\u001b[0m\n\u001b[0;32m 1033\u001b[0m w\u001b[38;5;241m.\u001b[39mdaemon \u001b[38;5;241m=\u001b[39m \u001b[38;5;28;01mTrue\u001b[39;00m\n\u001b[0;32m 1034\u001b[0m \u001b[38;5;66;03m# NB: Process.start() actually take some time as it needs to\u001b[39;00m\n\u001b[0;32m 1035\u001b[0m \u001b[38;5;66;03m# start a process and pass the arguments over via a pipe.\u001b[39;00m\n\u001b[0;32m 1036\u001b[0m \u001b[38;5;66;03m# Therefore, we only add a worker to self._workers list after\u001b[39;00m\n\u001b[0;32m 1037\u001b[0m \u001b[38;5;66;03m# it started, so that we do not call .join() if program dies\u001b[39;00m\n\u001b[0;32m 1038\u001b[0m \u001b[38;5;66;03m# before it starts, and __del__ tries to join but will get:\u001b[39;00m\n\u001b[0;32m 1039\u001b[0m \u001b[38;5;66;03m# AssertionError: can only join a started process.\u001b[39;00m\n\u001b[1;32m-> 1040\u001b[0m \u001b[43mw\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mstart\u001b[49m\u001b[43m(\u001b[49m\u001b[43m)\u001b[49m\n\u001b[0;32m 1041\u001b[0m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39m_index_queues\u001b[38;5;241m.\u001b[39mappend(index_queue)\n\u001b[0;32m 1042\u001b[0m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39m_workers\u001b[38;5;241m.\u001b[39mappend(w)\n",
"File \u001b[1;32mc:\\Users\\Cxyoz\\.conda\\py-133-pytorch\\Lib\\multiprocessing\\process.py:121\u001b[0m, in \u001b[0;36mBaseProcess.start\u001b[1;34m(self)\u001b[0m\n\u001b[0;32m 118\u001b[0m \u001b[38;5;28;01massert\u001b[39;00m \u001b[38;5;129;01mnot\u001b[39;00m _current_process\u001b[38;5;241m.\u001b[39m_config\u001b[38;5;241m.\u001b[39mget(\u001b[38;5;124m'\u001b[39m\u001b[38;5;124mdaemon\u001b[39m\u001b[38;5;124m'\u001b[39m), \\\n\u001b[0;32m 119\u001b[0m \u001b[38;5;124m'\u001b[39m\u001b[38;5;124mdaemonic processes are not allowed to have children\u001b[39m\u001b[38;5;124m'\u001b[39m\n\u001b[0;32m 120\u001b[0m _cleanup()\n\u001b[1;32m--> 121\u001b[0m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39m_popen \u001b[38;5;241m=\u001b[39m \u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_Popen\u001b[49m\u001b[43m(\u001b[49m\u001b[38;5;28;43mself\u001b[39;49m\u001b[43m)\u001b[49m\n\u001b[0;32m 122\u001b[0m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39m_sentinel \u001b[38;5;241m=\u001b[39m \u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39m_popen\u001b[38;5;241m.\u001b[39msentinel\n\u001b[0;32m 123\u001b[0m \u001b[38;5;66;03m# Avoid a refcycle if the target function holds an indirect\u001b[39;00m\n\u001b[0;32m 124\u001b[0m \u001b[38;5;66;03m# reference to the process object (see bpo-30775)\u001b[39;00m\n",
"File \u001b[1;32mc:\\Users\\Cxyoz\\.conda\\py-133-pytorch\\Lib\\multiprocessing\\context.py:224\u001b[0m, in \u001b[0;36mProcess._Popen\u001b[1;34m(process_obj)\u001b[0m\n\u001b[0;32m 222\u001b[0m \u001b[38;5;129m@staticmethod\u001b[39m\n\u001b[0;32m 223\u001b[0m \u001b[38;5;28;01mdef\u001b[39;00m \u001b[38;5;21m_Popen\u001b[39m(process_obj):\n\u001b[1;32m--> 224\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[43m_default_context\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mget_context\u001b[49m\u001b[43m(\u001b[49m\u001b[43m)\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mProcess\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43m_Popen\u001b[49m\u001b[43m(\u001b[49m\u001b[43mprocess_obj\u001b[49m\u001b[43m)\u001b[49m\n",
"File \u001b[1;32mc:\\Users\\Cxyoz\\.conda\\py-133-pytorch\\Lib\\multiprocessing\\context.py:336\u001b[0m, in \u001b[0;36mSpawnProcess._Popen\u001b[1;34m(process_obj)\u001b[0m\n\u001b[0;32m 333\u001b[0m \u001b[38;5;129m@staticmethod\u001b[39m\n\u001b[0;32m 334\u001b[0m \u001b[38;5;28;01mdef\u001b[39;00m \u001b[38;5;21m_Popen\u001b[39m(process_obj):\n\u001b[0;32m 335\u001b[0m \u001b[38;5;28;01mfrom\u001b[39;00m \u001b[38;5;21;01m.\u001b[39;00m\u001b[38;5;21;01mpopen_spawn_win32\u001b[39;00m \u001b[38;5;28;01mimport\u001b[39;00m Popen\n\u001b[1;32m--> 336\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[43mPopen\u001b[49m\u001b[43m(\u001b[49m\u001b[43mprocess_obj\u001b[49m\u001b[43m)\u001b[49m\n",
"File \u001b[1;32mc:\\Users\\Cxyoz\\.conda\\py-133-pytorch\\Lib\\multiprocessing\\popen_spawn_win32.py:95\u001b[0m, in \u001b[0;36mPopen.__init__\u001b[1;34m(self, process_obj)\u001b[0m\n\u001b[0;32m 93\u001b[0m \u001b[38;5;28;01mtry\u001b[39;00m:\n\u001b[0;32m 94\u001b[0m reduction\u001b[38;5;241m.\u001b[39mdump(prep_data, to_child)\n\u001b[1;32m---> 95\u001b[0m \u001b[43mreduction\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mdump\u001b[49m\u001b[43m(\u001b[49m\u001b[43mprocess_obj\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mto_child\u001b[49m\u001b[43m)\u001b[49m\n\u001b[0;32m 96\u001b[0m \u001b[38;5;28;01mfinally\u001b[39;00m:\n\u001b[0;32m 97\u001b[0m set_spawning_popen(\u001b[38;5;28;01mNone\u001b[39;00m)\n",
"File \u001b[1;32mc:\\Users\\Cxyoz\\.conda\\py-133-pytorch\\Lib\\multiprocessing\\reduction.py:60\u001b[0m, in \u001b[0;36mdump\u001b[1;34m(obj, file, protocol)\u001b[0m\n\u001b[0;32m 58\u001b[0m \u001b[38;5;28;01mdef\u001b[39;00m \u001b[38;5;21mdump\u001b[39m(obj, file, protocol\u001b[38;5;241m=\u001b[39m\u001b[38;5;28;01mNone\u001b[39;00m):\n\u001b[0;32m 59\u001b[0m \u001b[38;5;250m \u001b[39m\u001b[38;5;124;03m'''Replacement for pickle.dump() using ForkingPickler.'''\u001b[39;00m\n\u001b[1;32m---> 60\u001b[0m \u001b[43mForkingPickler\u001b[49m\u001b[43m(\u001b[49m\u001b[43mfile\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mprotocol\u001b[49m\u001b[43m)\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mdump\u001b[49m\u001b[43m(\u001b[49m\u001b[43mobj\u001b[49m\u001b[43m)\u001b[49m\n",
"\u001b[1;31mAttributeError\u001b[0m: Can't pickle local object 'get_dataset.<locals>.<lambda>'"
]
}
],
"source": [
"for epoch in range(1, total_epochs):\n",
" torch.cuda.empty_cache()\n",
" gc.collect()\n",
" \n",
" # Algorithm 1: Training\n",
" train_one_epoch(model, sd, dataloader, optimizer, scaler, loss_fn, epoch=epoch)\n",
"\n",
" if epoch % 20 == 0:\n",
" save_path = os.path.join(log_dir, f\"{epoch}{ext}\")\n",
" \n",
" # Algorithm 2: Sampling\n",
" reverse_diffusion(model, sd, timesteps=TrainingConfig.TIMESTEPS, num_images=32, generate_video=generate_video,\n",
" save_path=save_path, img_shape=TrainingConfig.IMG_SHAPE, device=BaseConfig.DEVICE,\n",
" )\n",
"\n",
" # clear_output()\n",
" checkpoint_dict = {\n",
" \"opt\": optimizer.state_dict(),\n",
" \"scaler\": scaler.state_dict(),\n",
" \"model\": model.state_dict()\n",
" }\n",
" torch.save(checkpoint_dict, os.path.join(checkpoint_dir, \"ckpt.tar\"))\n",
" del checkpoint_dict"
]
2024-03-31 14:51:57 +02:00
}
],
"metadata": {
"kernelspec": {
"display_name": "DLML",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
2024-04-01 00:16:59 +02:00
"version": "3.11.8"
2024-03-31 14:51:57 +02:00
}
},
"nbformat": 4,
"nbformat_minor": 2
}